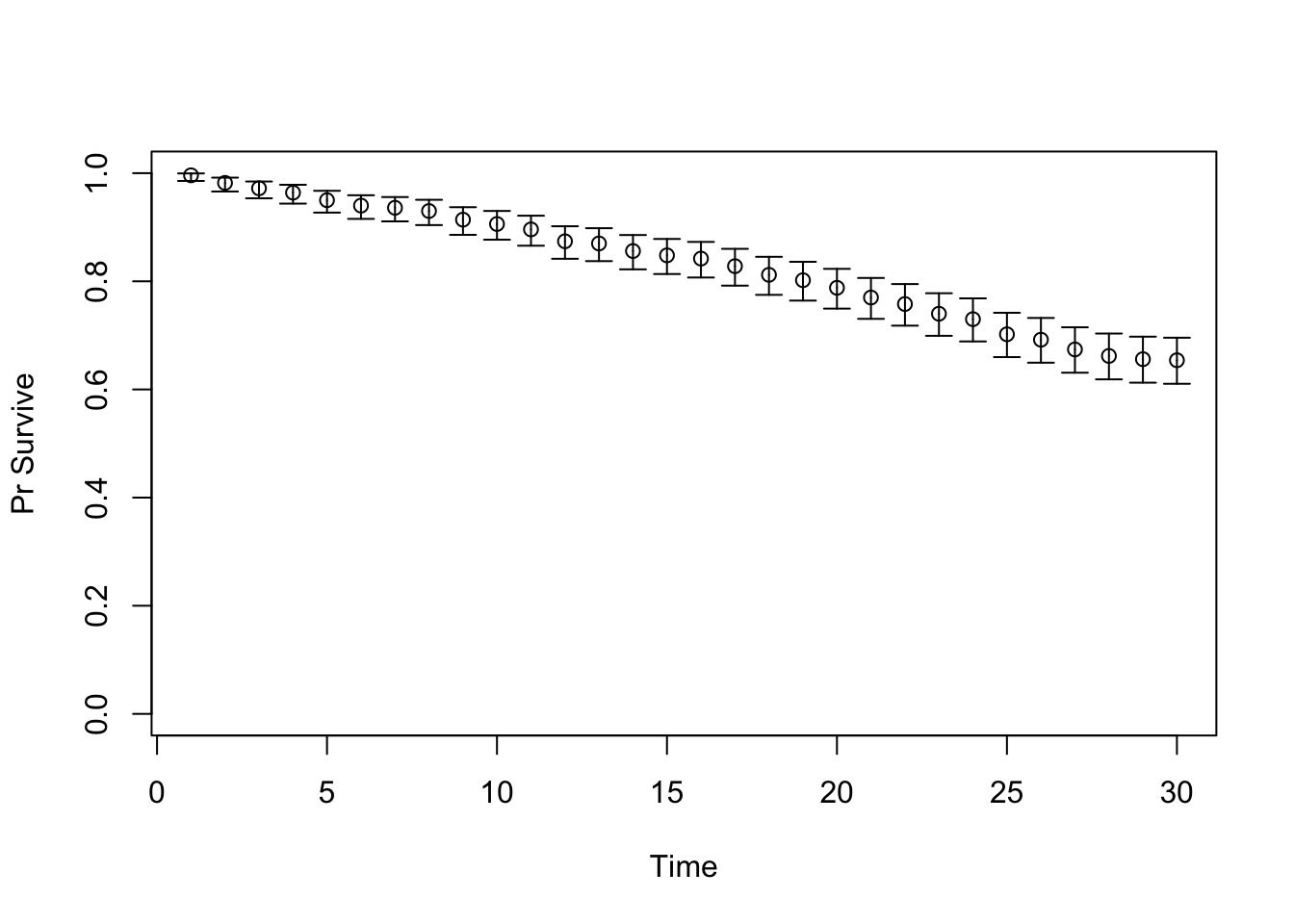
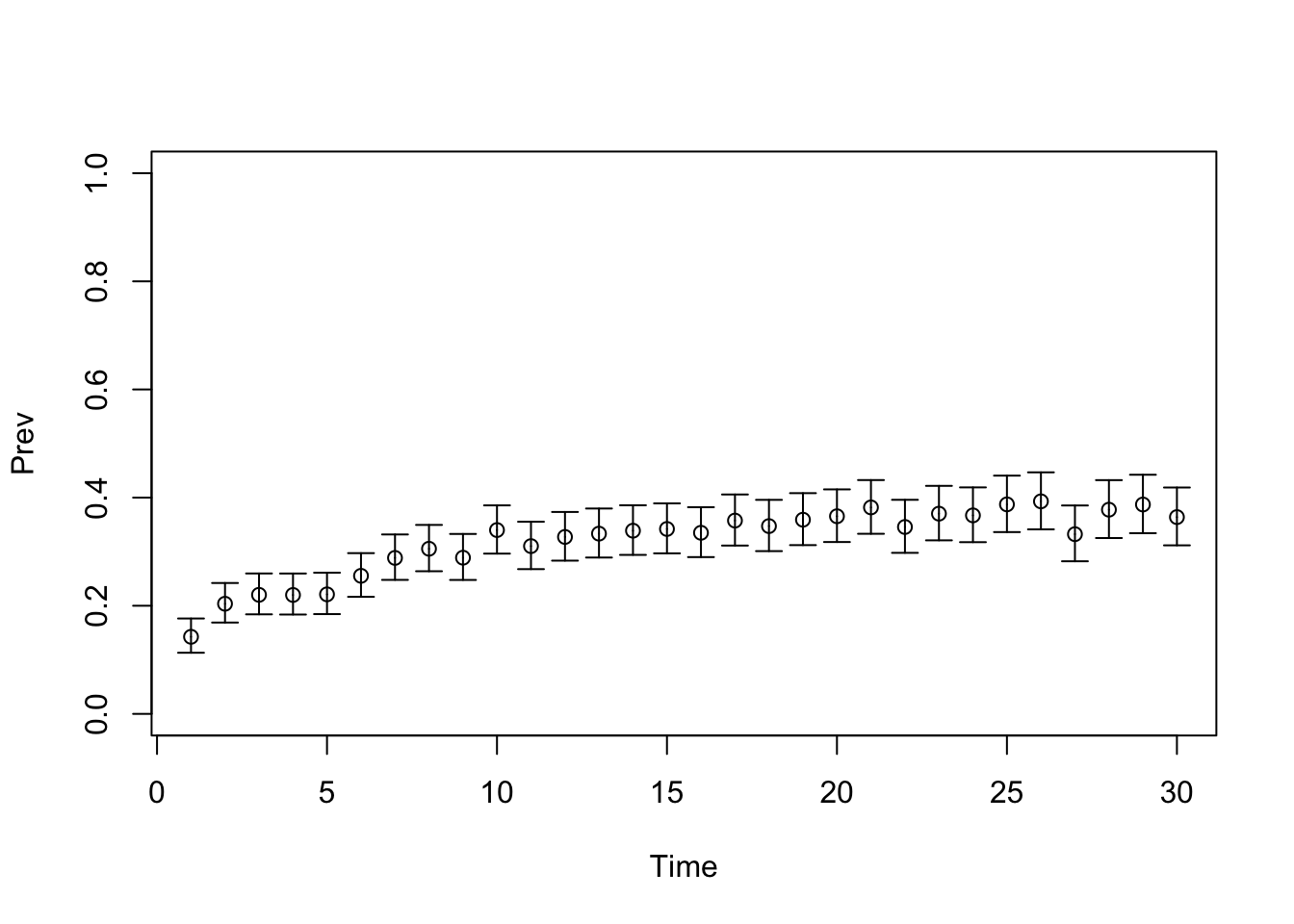
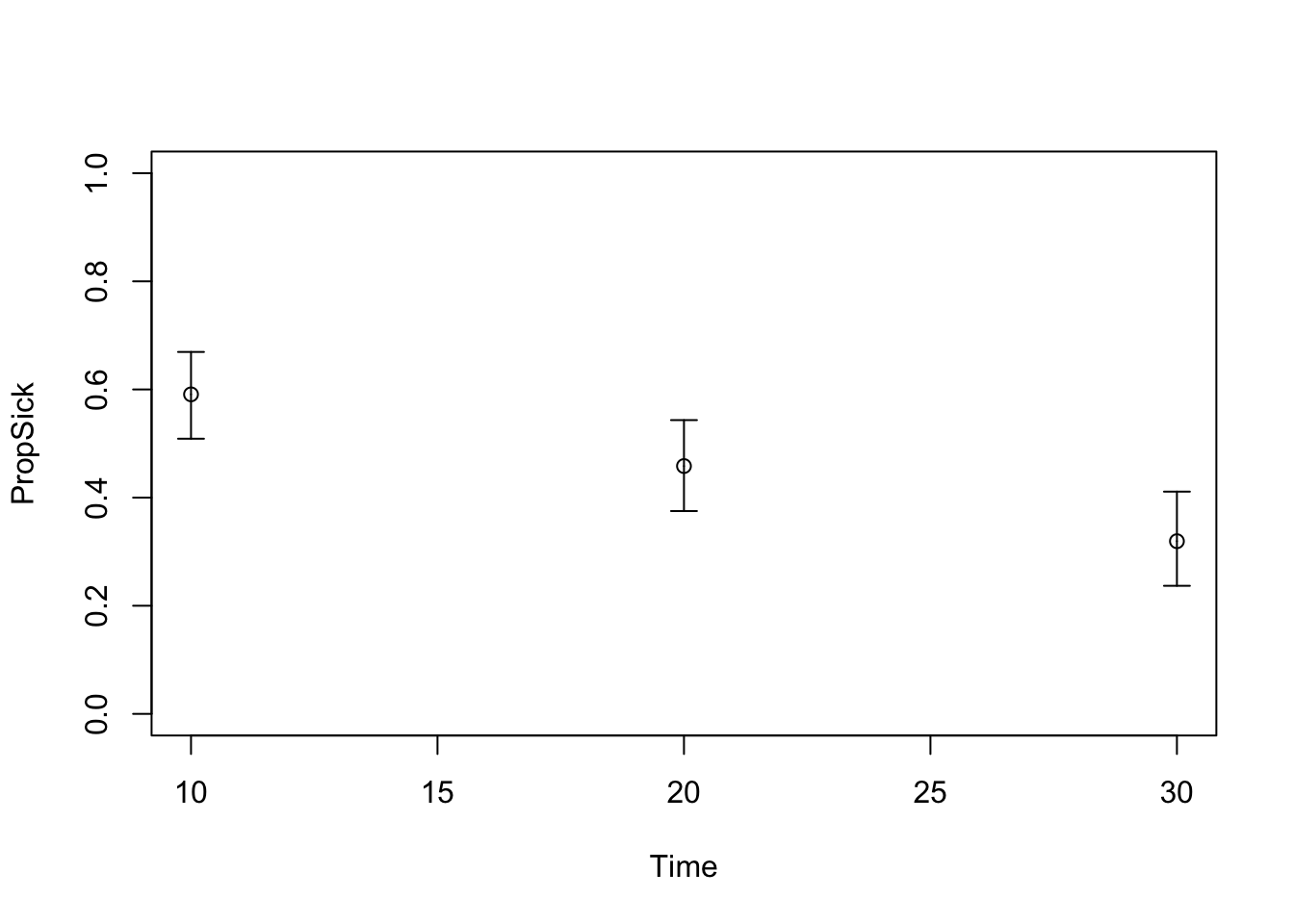
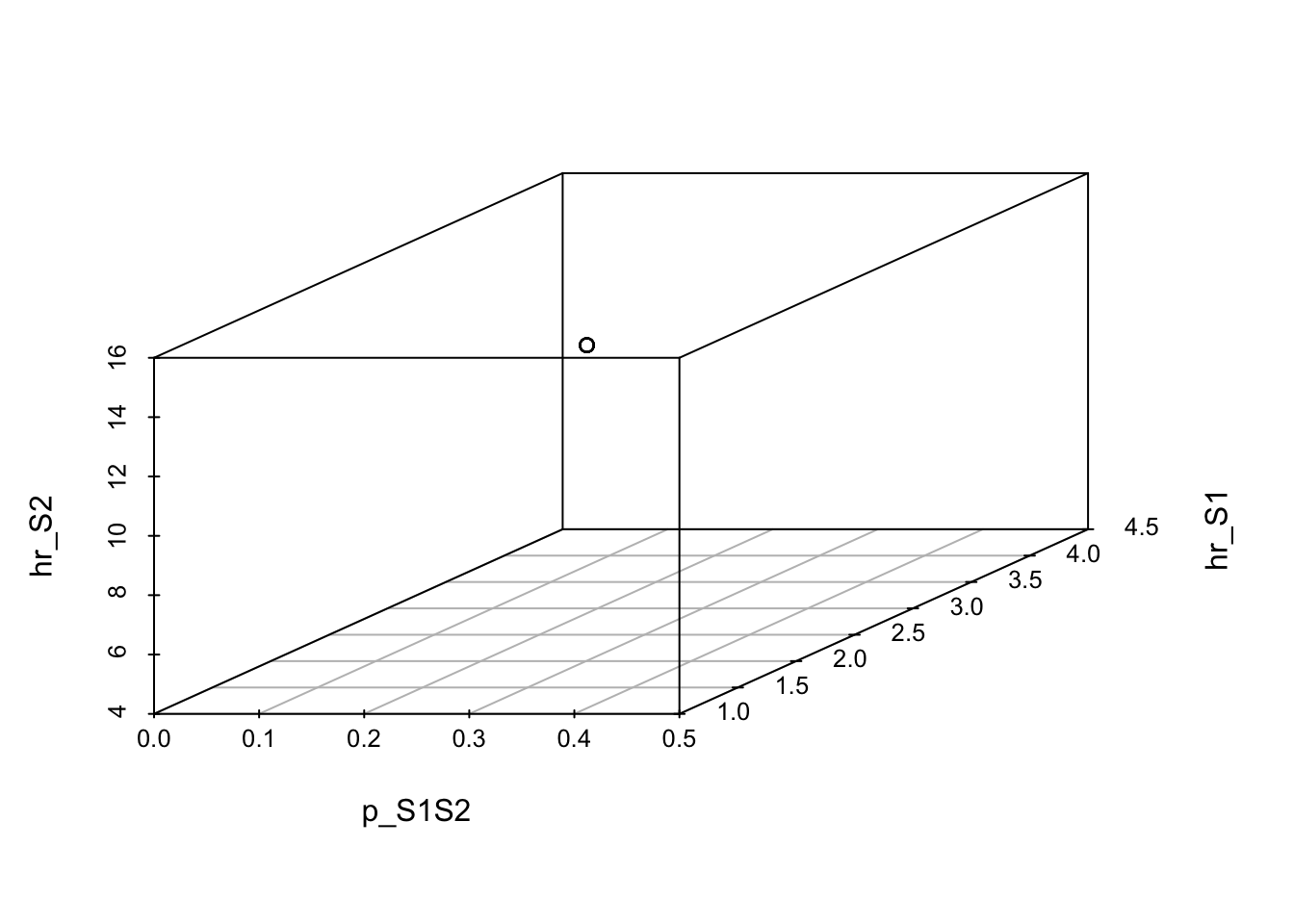
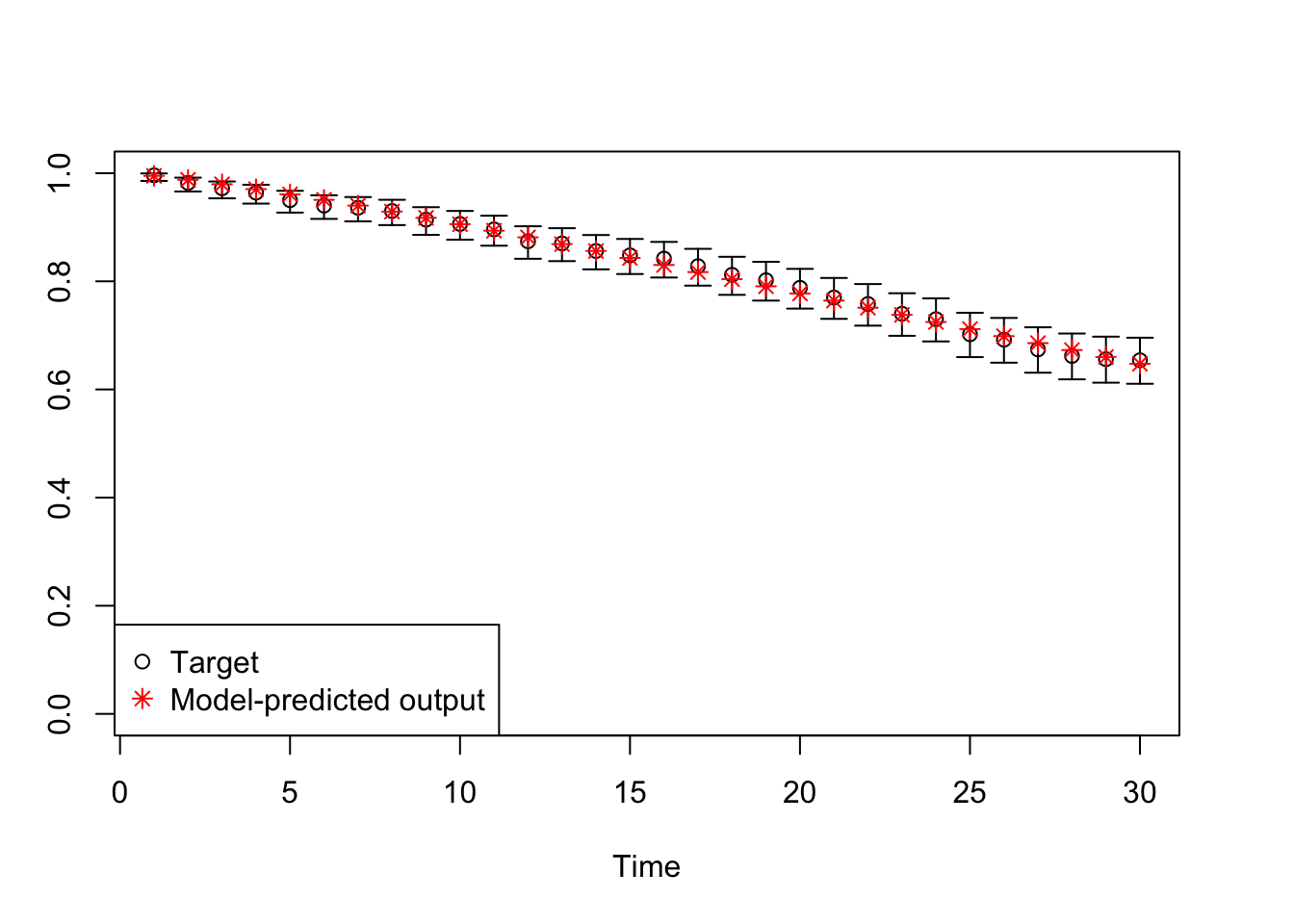
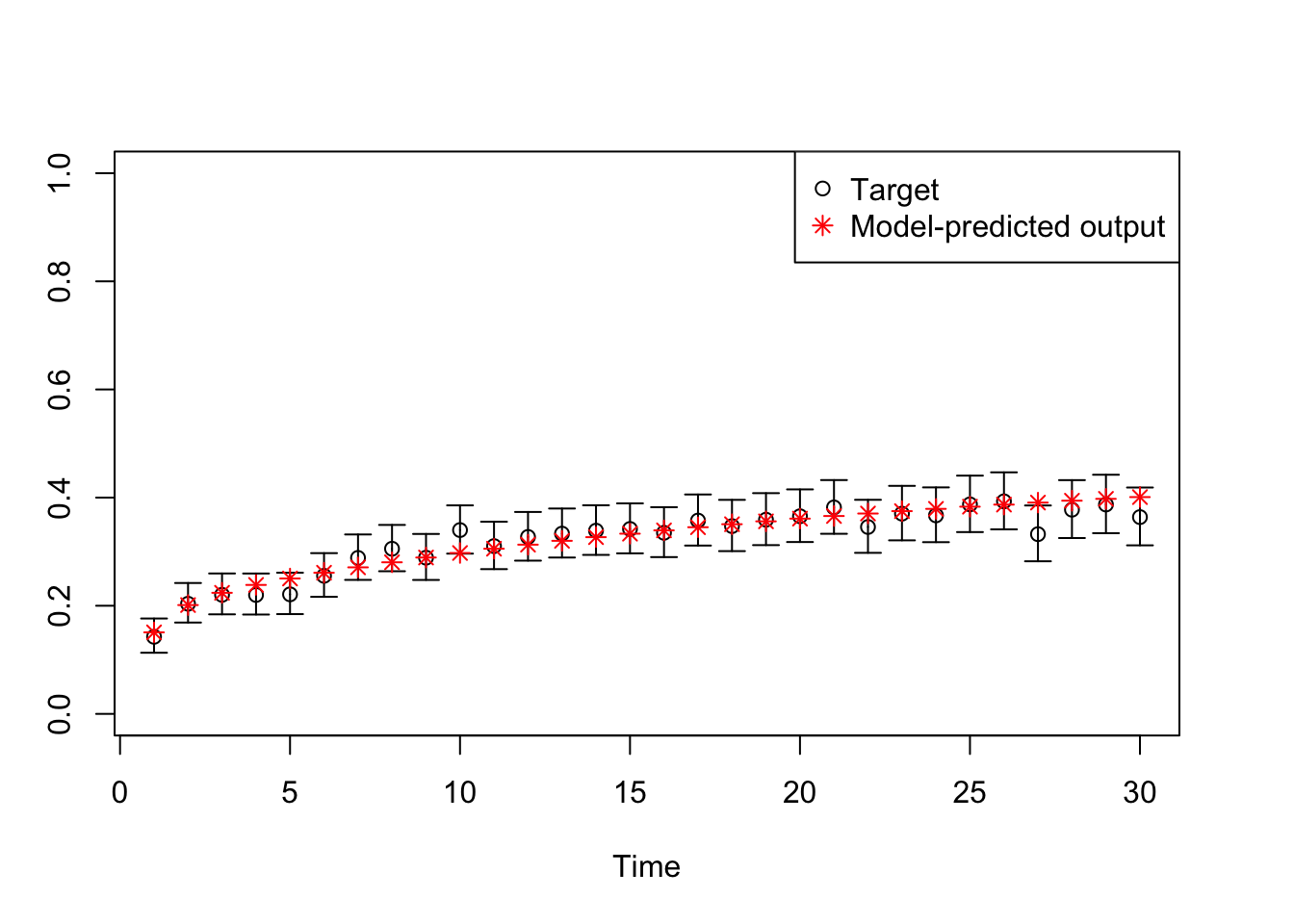
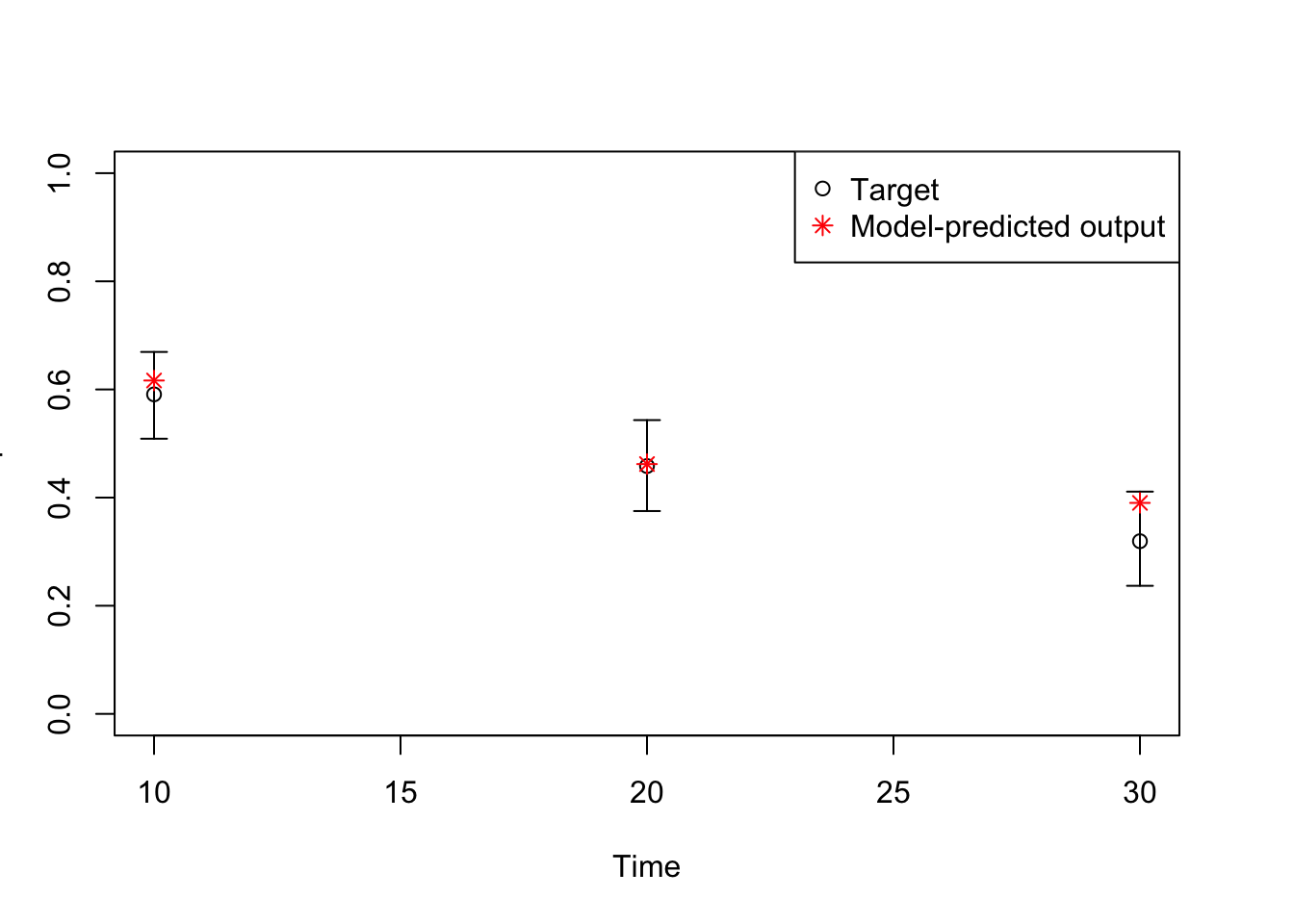
# TARGET 3: Proportion who are Sick ("PropSick"), among all those afflicted (Sick+Sicker)plotrix::plotCI(x = lst_targets$PropSick$time, y = lst_targets$PropSick$value,ui = lst_targets$PropSick$ub,li = lst_targets$PropSick$lb,ylim =c(0, 1),xlab ="Time", ylab ="PropSick")
04 Load model as a function
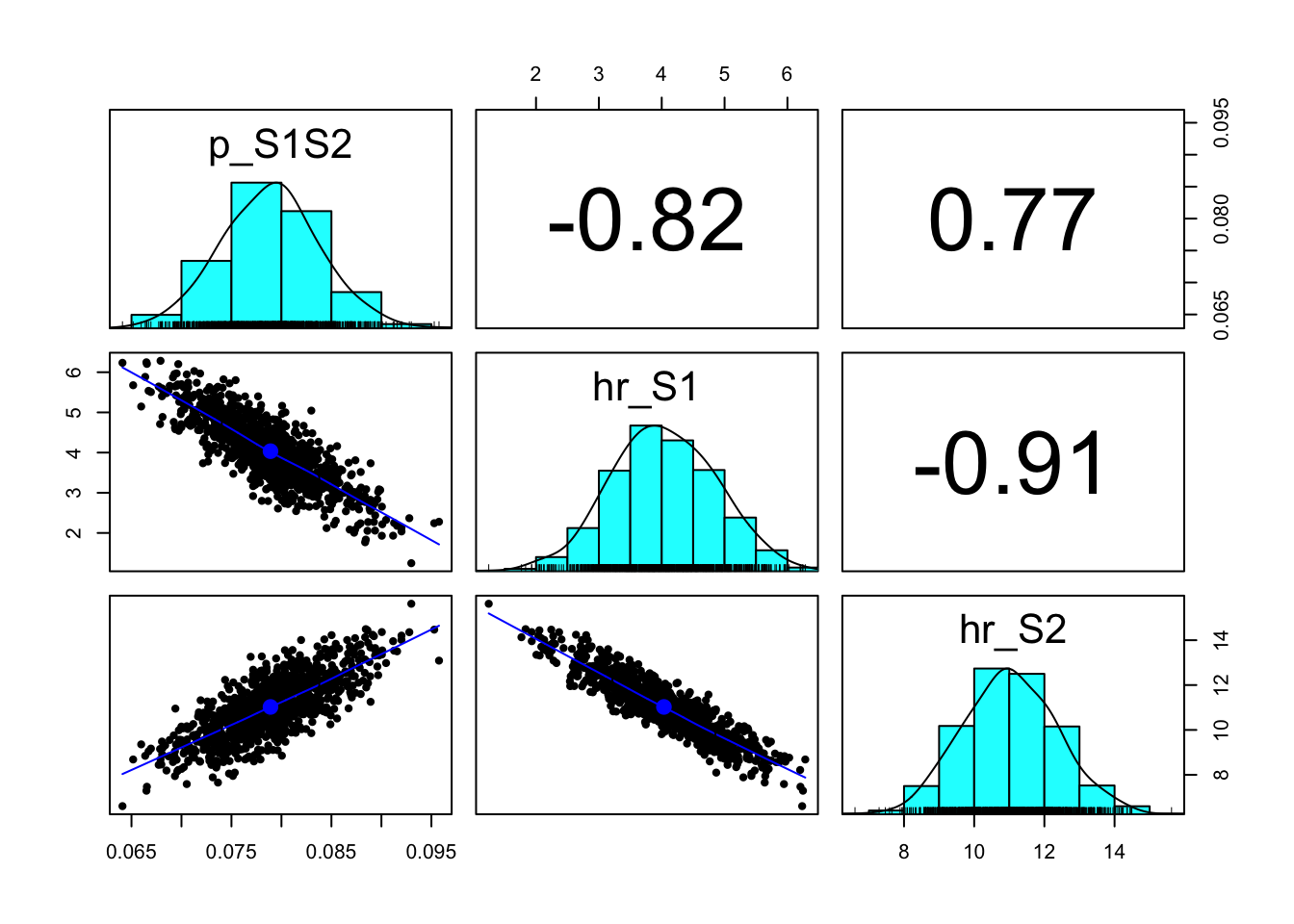
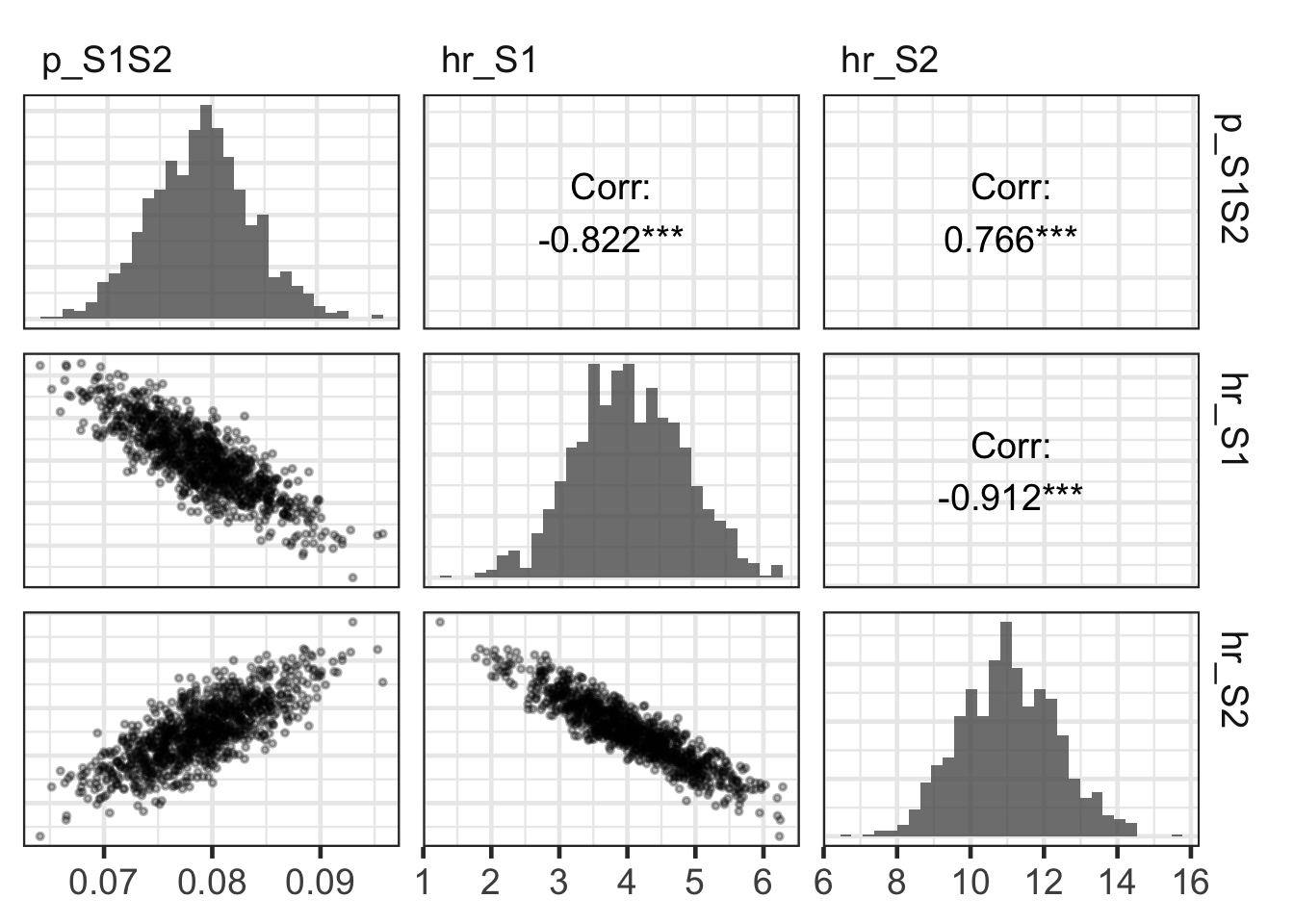
# ******************************************************************************# 04 Load model as a function --------------------------------------------------# ******************************************************************************### 04.01 Source model function -----------------------------------------------# Function inputs: parameters to be estimated through calibration# Function outputs: model predictions corresponding to target datasource("code/functions/SickSicker_MarkovModel_Function.R") # creates run_sick_sicker_markov()### 04.02 Test model function -------------------------------------------------v_params_test <-c(p_S1S2 =0.105, hr_S1 =3, hr_S2 =10)run_sick_sicker_markov(v_params_test) # Test: function works correctly
# check if hessian is negative definiteeigen(m_hess)$values
[1] -4.188857e-01 -1.180140e+01 -1.367698e+05
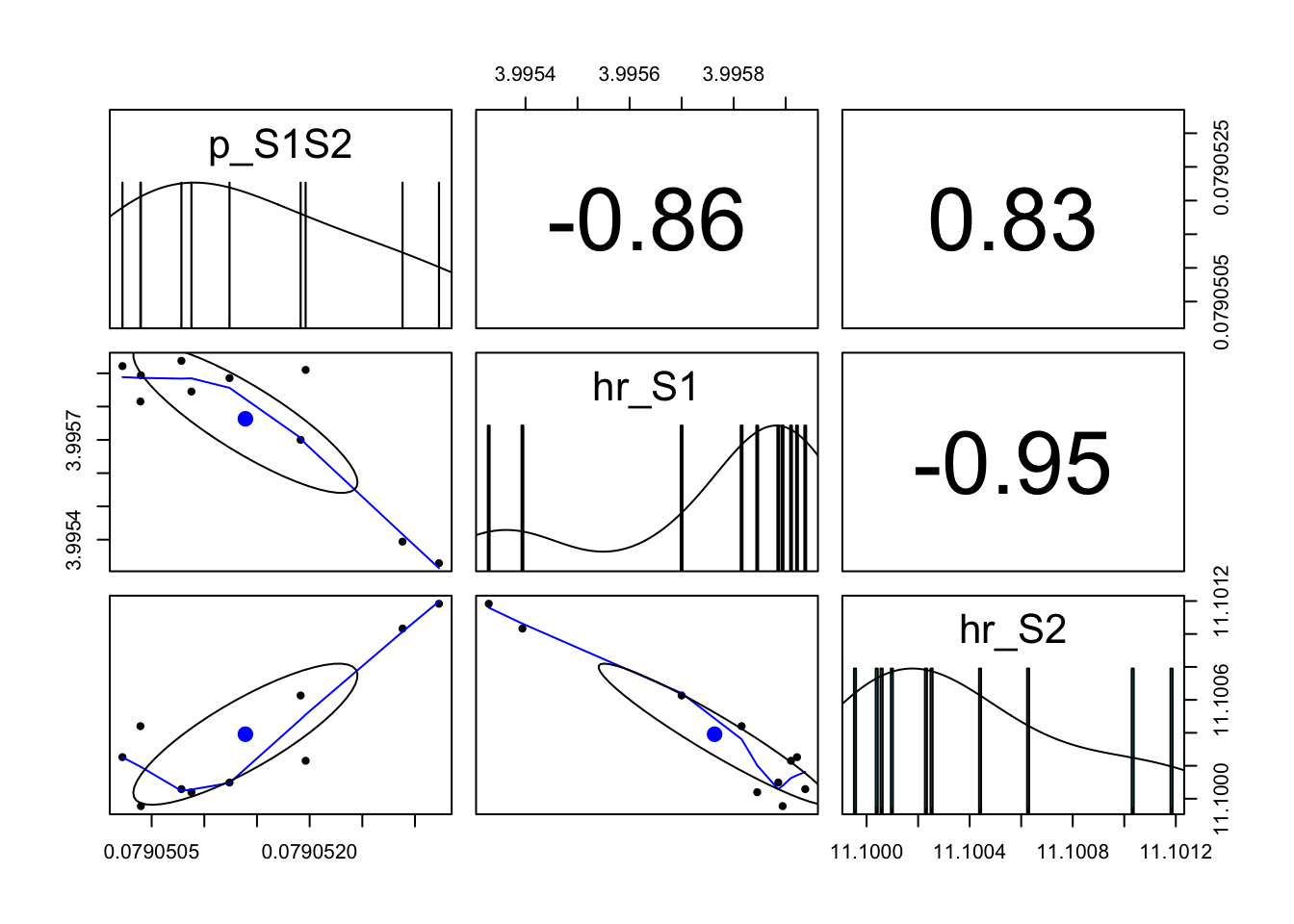
### 09.02 Covariance matrix ---------------------------------------------------# Check if HESSIAN is Positive Definite; If not, make covariance # Positive Definite# Is Positive Definite?if (!is.positive.definite(-m_hess)) {print("Hessian is NOT Positive Definite") m_cov <-solve(-m_hess)print("Compute nearest positive definite matrix for COV matrix using `nearPD` function") m_cov <- Matrix::nearPD(m_cov)$mat} else{print("Hessian IS Positive Definite")print("No additional adjustment to COV matrix") m_cov <-solve(-m_hess)}
[1] "Hessian IS Positive Definite"
[1] "No additional adjustment to COV matrix"
`stat_bin()` using `bins = 30`. Pick better value `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value `binwidth`.
Note: This exercise demonstrates calibration using the Nelder-Mead algorithm via the optim() function in R. This method is a local search algorithm and depends on the initial values provided.